

Why Error Correction Is So Expensive
And Why We Need It

First up, If you’d like to support our equipment fundraiser, you’ll find the link here. And now, today’s post!
We’ve seen in earlier posts that staggering numbers of qubits are required for error correction. Time now to deep dive this.
We’ve established that logic errors are inevitable, direct measurement is forbidden, protection requires encoding across many qubits and it all makes sense. Then someone tells you how many physical qubits a useful fault-tolerant quantum computer actually requires, and the scale of the engineering challenge becomes suddenly, uncomfortably real.
It’s worth sitting with that discomfort for a moment or two. The expense of quantum error correction is not a temporary embarrassment that better engineering will soon eliminate. It is baked into the physics. Understanding why the cost is so high and why we pay it anyway, is essential to understanding where quantum computing actually stands and where it is going.
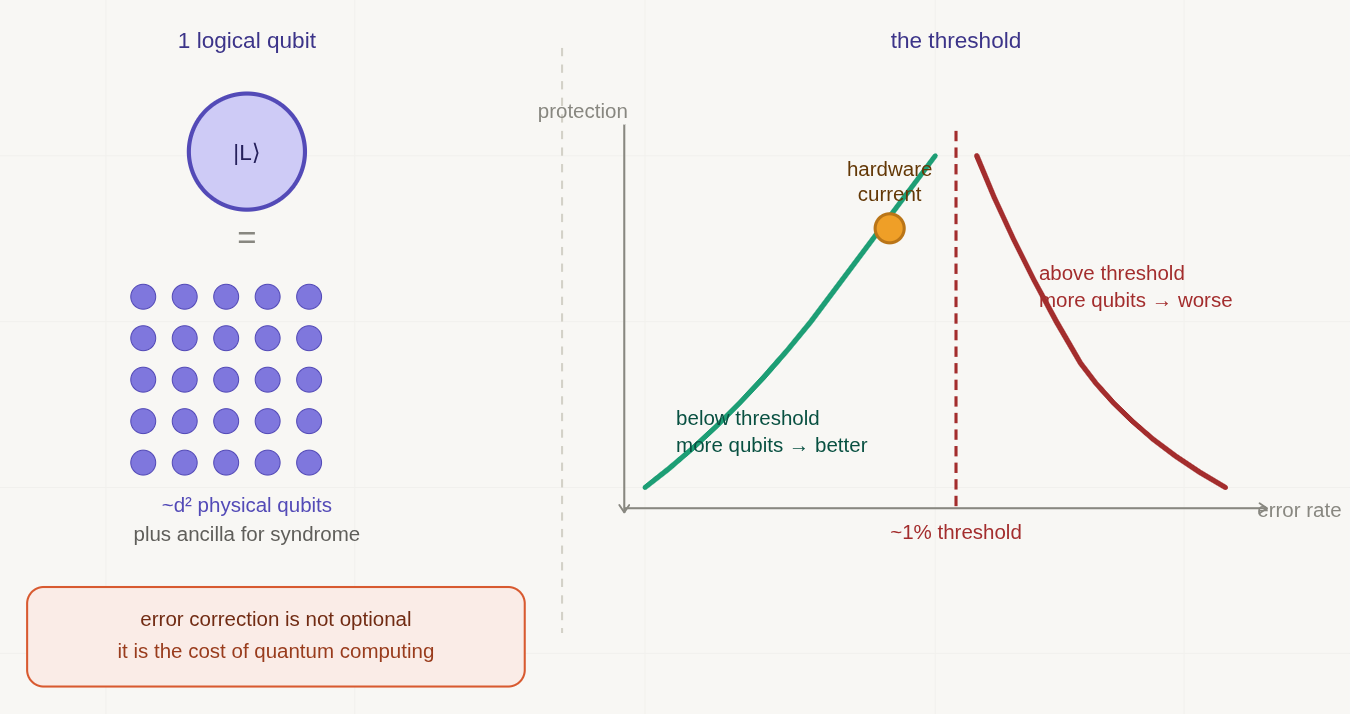
We’ve established that a logical qubit, the protected, reliable unit of quantum information that algorithms actually use, is encoded across many physical qubits. For a surface code of distance d, the number of physical qubits required per logical qubit scales as roughly d².
What does distance need to be in practice? That depends on the error rate of the physical hardware and the length of the computation you want to run. Current physical qubit error rates, on the best available hardware, sit somewhere around one part in a thousand per operation.
A distance-20 surface code1 requires around 800 physical qubits per logical qubit. A useful algorithm might need hundreds of logical qubits. We are now in the regime of hundreds of thousands to millions of physical qubits just for a single computation.
Current quantum processors, the most advanced in the world, have on the order of one to a few thousand physical qubits. The gap between where we are and where fault tolerant computation requires us to be; is not a rounding error. It is several orders of magnitude and physical qubit count is only part of the cost. The other part is time.
Quantum error correction is not a one time operation performed at the start of a computation. It runs continuously, cycle after cycle, for the entire duration of the algorithm. Every syndrome measurement round consumes time. Every correction operation consumes time. The logical qubit is being actively maintained throughout; not passively stored, but constantly monitored and repaired.
This continuous correction cycle introduces a significant slowdown. A logical operation such as a gate applied to a logical qubit doesn’t execute in the time it takes to perform the equivalent physical operation. It executes over many rounds of error correction, each round consuming physical gate time. The effective clock speed of a fault-tolerant logical quantum computer is substantially lower than the raw clock speed of its physical hardware.
The hardware runs fast. The logical computation runs slow. The gap between them is filled with error correction overhead.
And this overhead compounds. More complex algorithms require more logical qubits, more operations, longer run times; each of which demands more error correction cycles, which demands more physical qubits running for longer. The resource requirements scale in ways that make even moderately ambitious computations very demanding indeed.
Against all of this, there is one result that makes fault tolerant quantum computing worth pursuing at all. It is called the threshold theorem, and it is the theoretical foundation on which the entire enterprise rests.
The threshold theorem states, roughly, that if the error rate of individual physical operations falls below a certain critical value, then the ‘threshold’, then it becomes possible, in principle, to perform arbitrarily long quantum computations reliably, by using sufficiently large error correcting codes.
Below the threshold: more qubits means better protection. You can make the logical error rate as small as you like by scaling up the code. Fault tolerance is achievable.
Above the threshold: more qubits makes things worse. The error correction machinery itself introduces more errors than it removes. No amount of scaling helps. Fault tolerance is impossible.
The threshold is not a single number. It depends on the specific code, the specific hardware, and the specific error model. For surface codes under realistic assumptions, it sits at roughly one percent per physical operation. Current best hardware is approaching this number. Some platforms have demonstrated physical error rates below threshold on individual operations, though sustaining that performance across an entire processor at scale remains challenging.
The threshold theorem doesn’t tell you that fault tolerant computation is easy. It tells you that there exists a path from noisy physical hardware to reliable logical computation, however expensive that path may be. That existence proof is what justifies the enormous investment currently flowing into the field.
Error Correction Is Not Optional
It is occasionally suggested, usually by people with a stake in near term quantum devices, that error correction might be avoidable. That clever algorithms, better hardware, or hybrid classical quantum approaches might sidestep the need for full fault tolerance. This view deserves a fair hearing, and it contains a kernel of truth for certain limited applications.
But for the computations that would represent genuine, broad quantum advantage i.e. breaking cryptographic problems, simulating quantum chemistry at scale, solving optimization problems beyond classical reach, then the noise levels of unprotected physical qubits are simply too high. The computation would decohere before it completed. The answer would be buried in errors.
Error correction is not optional. It is the cost of doing quantum computing at scale.
This is not a counsel of despair. It is a statement about where the engineering effort needs to go. Every improvement in physical qubit quality reduces the overhead required. A physical error rate of one in ten thousand rather than one in a thousand dramatically reduces the code distance needed, which dramatically reduces the physical qubit count. Every advance in LDPC codes and alternative architectures offers routes to lower overhead. Every improvement in fabrication and connectivity brings the required hardware closer to achievable.
The economics are brutal but not fixed. They are improving, and the direction of improvement is clear.
The Real Machine
Step back and consider what a fault tolerant quantum computer actually looks like as a system.
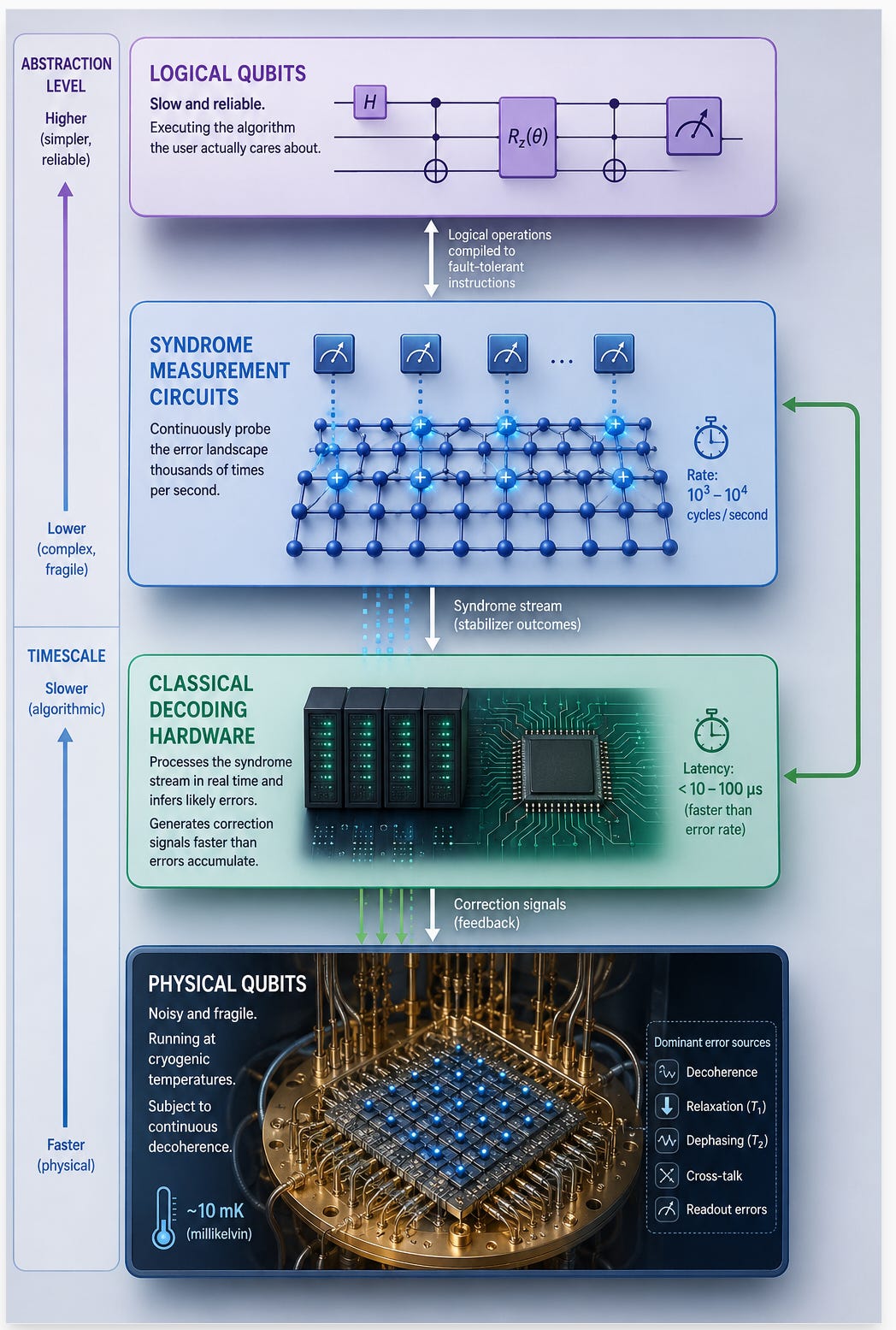
At the bottom layer: physical qubits, noisy and fragile, running at cryogenic temperatures, subject to continuous decoherence. Above them: syndrome measurement circuits, sampling the error landscape thousands of times per second. Alongside them: classical decoding hardware, processing the syndrome stream in real time and generating correction signals faster than errors accumulate. At the top: logical qubits, slow and reliable, executing the algorithm the user actually cares about.
This is not a single device. It is a tightly integrated stack. That is, quantum hardware, classical control, real time decoding, logical abstraction. All operating as a unified system in which every layer depends on every other. The quantum many body systems being developed for sensing and simulation inhabit this same stack. Error correction in those contexts is not a feature bolted on after the fact. It is a continuous process woven into the operation of the device itself. That is, a hybrid quantum-classical loop running underneath everything else.
The expense is real. The necessity is real. And the machinery for meeting that necessity is, piece by piece, being built.
What remains is to step back further and to ask not just how we protect information, but what it means to represent it in the first place. That more philosophical question turns out to have practical consequences, and it’s where we go next.
That’s all for now! If you like my efforts to make quantum science, computing and physical chemistry, more accessible to everyone; please consider recommending this newsletter on your own substack or website. Or share ExoArtDataPulse with a friend or colleague. Every recommend makes the project grow. Thanks for Reading!
Support our workstation fundraiser here :-)
The distance of a surface code is the minimum number of physical qubit errors required to produce an undetectable logical error; a distance-d code can correct up to ⌊(d−1)/2⌋ errors. For a distance-20 surface code, this means up to 9 simultaneous physical errors can be corrected per logical qubit cycle.
The code is arranged as a 2D lattice of data qubits interleaved with measurement (ancilla) qubits. A distance-d lattice requires approximately d² data qubits plus a comparable number of ancillae, giving roughly 2d² physical qubits in total. At d = 20, this yields approximately 800 physical qubits per logical qubit; a figure consistent with current threshold estimates assuming physical error rates in the range of 10⁻³.
The overhead scales as d² because larger lattices provide more redundancy and therefore greater protection, but the number of components grows with the area of the code patch. See Fowler, A. G. et al., "Surface codes: Towards practical large-scale quantum computation," Physical Review A 86, 032324 (2012) for a comprehensive treatment.