

We Can’t Copy a Qubit!
The Strange Rules of Protection

Before we start, I’ve recently launched a crowdfunding campaign to fund our much needed workstation project. Just to recap, the kit we desperately need is a fast, well built PC with dual monitors, one for the experiments and the other for the results, and writing and documentation. We also need an uninterruptible power supply (UPS) and two large, fast data disks for professional level data analysis and daily, weekly and monthly backups. If you’d like to pitch in and help, you’ll find the link here.
And now, today’s post!
Think about how we protect important information in the classical world. We back up our hard drive. We make copies of documents. We store duplicates in different locations. When a file gets corrupted, we reach for the backup. When a bit flips in transmission, we compare it against two redundant copies and take the majority vote.
Copying is so fundamental to classical error correction that it’s almost invisible1. It’s the assumption underneath everything i.e. that information can be read, duplicated, and checked without disturbing the original. The whole architecture of data protection rests on it.
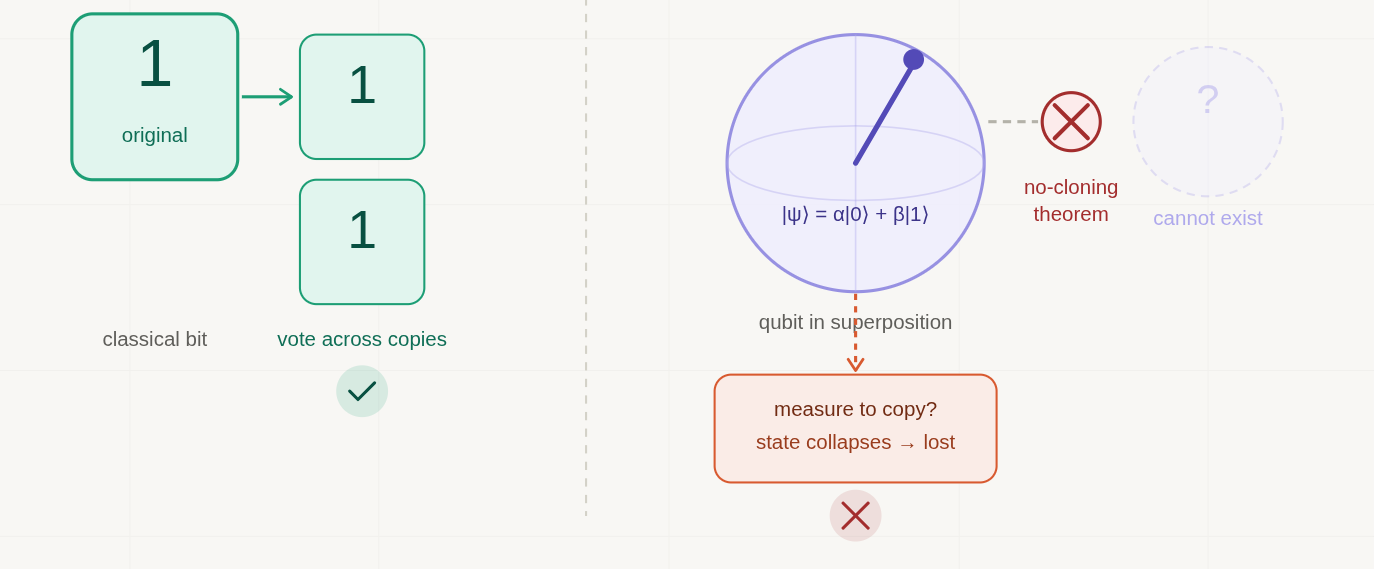
Classical redundancy is elegant in its simplicity. Take a single bit, say, a 1. Encode it as three copies, 1 1 1. If noise flips one of them, we end up with something like 1 0 1. We look at all three, take the majority vote, and recover 1. The error is corrected. The original information survives.
The whole scheme rests on two assumptions. First, we can read the bits without disturbing them. Second, we can copy them freely before transmission or storage. Neither of these is exotic in classical computing. Both of them collapse in the quantum world.
Unfortunately, the workings of Quantum mechanics makes copying illegal!
In 1982, William Wootters and Wojciech Zurek proved something that, on first encounter, feels like it shouldn’t be true. i.e. it is physically impossible to create a perfect copy of an unknown quantum state.
This isn’t a limitation of current technology. It’s not an engineering problem waiting for a better machine. It’s a theorem and a consequence of the linearity of quantum mechanics. We cannot duplicate a qubit the way we duplicate a classical bit. Not now, not ever, not with any device that obeys the laws of quantum physics.
The intuition runs something like this. To copy something, we first have to know what it is. But to know what an arbitrary qubit’s state is, we’d have to measure it. And measurement, in quantum mechanics, doesn’t passively read information, it actively transforms the system. A superposition, once measured, collapses. The very act of looking destroys the thing you were trying to copy.
So the classical playbook i.e. read it, copy it, compare the copies, is simply unavailable. Quantum error correction has to be built on entirely different foundations.
Here’s the rub. When we read a classical bit, we find out what it is and it stays what it is. The readout is passive. The bit doesn’t care that we looked.
When we measure a qubit in superposition, we collapse it. We get a definite answer, for instance a 0 or 1, but the quantum information that was encoded in the superposition is gone. The phase relationships, the subtle weighting between states, the entanglement with other qubits; all of it vanishes the moment we take a direct measurement.
This creates a profound problem for error correction. In the classical scheme, we detect errors by looking at the bits and comparing them. In the quantum case, looking at the qubit destroys the very information we’re trying to protect. You can’t check whether the state has been corrupted without corrupting it yourself.
It seems like an impossible situation. How do we protect something we’re forbidden to copy and forbidden to look at directly?
The answer quantum error correction eventually arrives at is indirect encoding. Instead of storing information in a single qubit that can be lost, flipped, or dephased; instead we spread it across many physical qubits in a carefully chosen pattern. The information lives in the relationships between them, not in any individual one.
This collective encoding is called a logical qubit. The logical qubit is the real carrier of our information. The physical qubits are its substrate. They are expendable, error prone components whose individual failures can be detected and corrected without ever directly touching the encoded state.
The distinction matters enormously. A physical qubit is fragile and real. A logical qubit is protected and abstract. Building reliable quantum computation means doing everything in terms of logical qubits, even though the machine only speaks the language of physical ones.
How many physical qubits does it take to encode one logical qubit reliably? That’s one of the central questions in the field and the answer is uncomfortably large. But we’re getting ahead of ourselves. The key insight for now is this. We must protect information without ever fully seeing it.
That sounds paradoxical. But there turns out to be a way, a method that lets us detect errors without collapsing the state. We gather just enough information to diagnose a fault without revealing what we’re protecting. How do we spread information across many qubits to achieve that protection? That’s where we’re going next.
That’s all for now! If you like my efforts to make quantum science, computing and physical chemistry, more accessible to everyone; please consider recommending this newsletter on your own substack or website. Or share ExoArtDataPulse with a friend or colleague. Every recommend makes the project grow. Thanks for Reading!
Support our workstation fundraiser here :-)
Just for fun, make jot down a tick on a notepad every time you cut and paste while you’re typing, coding or searching for info on the web. Just imagine how tedious life would be if we had to backspace/rub everything out and retype it correctly, because copy, cut and paste didn’t exist. Copying is embedded in information processing, we’ve just gotten so used to it we don’t even see it.